Originally presented at SummerCon 2022

Where and when: Summercon 2022 (Brooklyn, NY) — Friday, July 8, 11:00 AM, Main Stage
Hi all — thanks for having me here. I’m Arya. I graduated with a mechanical engineering degree before making my way into security — firmly on the blue team side of the equation.
Having studied safety engineering and then going into security, I realized there are a lot of parallels. Engineering — especially mechanical, civil, industrial — also deals with risk. The stakes are high: buildings collapsing, chemical explosions, human tragedy. In mechanical engineering, we have robust protocols and controls in place to minimize these risks. Each and every one of these controls is written in blood: somewhere, something happened, and people died, or got hurt, and the industry came together to prevent it from happening again. In security, too, we learn from post-mortems, but thankfully, we almost never deal with the risk of human tragedy — I’m not equating the two. Though, there are areas like hospitals,air traffic control, critical infrastructure, medical devices, where a cybersecurity failure does put lives at risk.
In this talk, we’re going to go through a few engineering disasters. What lessons we have learned and how we can adapt these lessons to build actionable security measures in our organizations. I use these CONSTANTLY at my company, and I feel they’ve guided me well. By the end of this, I hope to empower you with three tools and ways of thinking that you can start using immediately in your security program.
Before we begin, a quick content note: I’m going to be talking about actual, real engineering disasters. In some of these cases, people have died, or been seriously injured. I’m not going to show any graphic images — but I will be talking details, and some of this content may be distressing. Please feel free to step out at any time, or skip this talk entirely; I totally understand.
Let’s start with a classic example, something I’m sure you’re all familiar with: the October 21st, 2016 incident at the MGPI processing facility in Atchison, Kansas. No? Okay, here’s what happened. In Kansas they got this big faciltiy that makes spirits, wheat protein, starch, a bunch of other stuff. If you’re not familiar with such facilities, they use pretty gnarly chemicals — even the ones that make food stuff.
This facility uses sodium hypochlorite (AKA bleach) and sulfuric acid. In case you didn’t know, never EVER mix sulphuric acid and bleach. It releases chlorine gas. Bad day for everyone.
 USCSB official report
USCSB official report
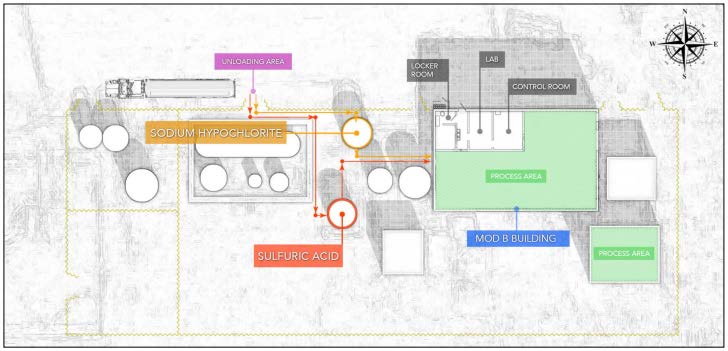
So this facility has these two massive tanks of acid and bleach [here and here]. (By the way, I stole this graphic from the US Chemical Safety Board’s official report.) They’re using them downstream for their chemical process, that part’s not relevant. What’s important here is that every once in a while someone needs to fill up these tanks, so they bring this big truck over here [points], hook up a hose to the correct pipe and fill up the tank.
This is what the fill lines look like. This is the acid [very briefly points to left connector]. This is the bleach [very briefly points to right connector]. On the day of the incident, the truck was supposed to load up sulfuric acid into the correct tank: connect the hose, start the pumps. Don’t fuck up! If you put acid in the bleach tank, you’re going to have a massive poison cloud enveloping the entire facility.
 USCSB official report
USCSB official report
I’ll keep you in suspense just a little while longer, but I have some food for thought for you — how many times have you almost fucked up bad? Almost typed in the wrong command maybe and you were in prod. Or you were just about to push something to git and then you realized that you got a credential file in there. Maybe you almost wiped a database. How many times have you come really close to disaster? Did it terrify you? Did it jolt you awake and you promised to yourself you were gonna pay more attention from now on? Or did you take the time to actually change your process to make sure it’s not possible to fuck up, even if you’re distracted?
Back to the fill lines. You’re the truck driver. You need to load up the sulfuric acid. I’m the operator of the facility — I just told you which pipe is the correct one. Do you remember? Is it this one? Or is it this one? Are you sure?
On the day of the incident, the truck driver connected the acid to the bleach tank, and began to pump. Chlorine gas started pouring out onto the facility. The driver tried to shut off the flow, but there was too much gas everywhere — he couldn’t. So the truck kept pumping acid into the bleach tank, This is the aftermath.
 USCSB
USCSB
That’s chlorine gas. Over 100 people needed medical attention, some ended up in the hospital. About 11000 residents had to evacuate or shelter in place. Thankfully nobody died.
What happened? You’re all familiar with a root cause analysis, so I won’t torture you with one. But you know the questions, you’ve done it a thousand times. Why did the truck driver fuck up? Why wasn’t the operator there to remind him which one is the correct one? Why was the operator even needed, why weren’t the pipes clearly marked? Why were they so close together? Why wasn’t the bleach pipe under lock and key? For that matter, why was it even possible to hook up the acid to the bleach line??? Why didn’t they use different connectors or something???
I’m sure you’ve done this 1000 times after a security incident. Your brains are probably buzzing right now with various blindingly obvious solutions for what is, in retrospect, something that was bound to happen eventually. With how things were set up, it was inevitable. If the only thing that stands between you and disaster is a “don’t fuck up!” in an environment that looks like it was intentionally designed to make you fuck up, you’re already doomed.
It was inevitable.
We once got an email from an engineer — they accidentally commited some credentials to a public repository. They were synchronizing some of their environment config between two different machines, and since they were so separated the most convenient way of doing it was to upload their config to github and to download it on the other machine. The repo was public because it’s just some emacs configs or whatever, who cares. They never intended to put credentials in the code, they knew full well the dangers of that. But they were troubleshooting something else, and they had some keys in their config files, and didn’t realize, and uploaded them to github. Bad news. They let us know, we rolled the keys, checked the logs, thankfully nothing bad happened.
But it was inevitable. There wasn’t a standard set of steps to synchronize environments between machines, there wasn’t something to prevent them from committing code to github. It’s not their fault — everyone fucks up eventually, no matter how hard you try not to.
I’ve talked to a bunch of sec people — everyone I know runs a post mortem in almost the exact same way. If something like that credential leak were to happen, there’d be a root cause analysis (just like we did) and there’d be solid recommendations across the board.
How do you control risk?
But obviously we prefer prevention, so how do you control risk? what do you do before an event happens? I had this conversation many times with security friends. Some people focused on human factors — after all, humans are often times the weak link in a process. Some talked about having robust alerting and visibility — if something bad happens, we need to know right away! Some mentioned moving security to the left, getting in early in the design process so we can design an inherently secure system. All amazing ideas — but I had lots of conversations, and there wasn’t a unified philosophy to risk reduction. Everyone had their own approach, and their own framework. I myself flip-flopped between different approaches.
We have some standards, but they’re all fairly recent, all things considered. We got the OWASP framework. We got SANS institute methodologies. We have NIST recommendations. Right now there’s push to implement more security regulation, to require certain approaches to minimizing security risks, but it’s all very tentative, and it’s all very unclear.
Which is a shame.
Because you can see similarities between that chlorine spill and that credential leak. Dealing with engineering hazards isn’t so different from dealing with risks in security.
And in the safety industry, they have a solid framework to deal with this. They’ve had it for a very long time, it’s implemented by virtually every regulatory body and organization out there. It’s mature. It’s solid. It’s informed public policy. It’s…
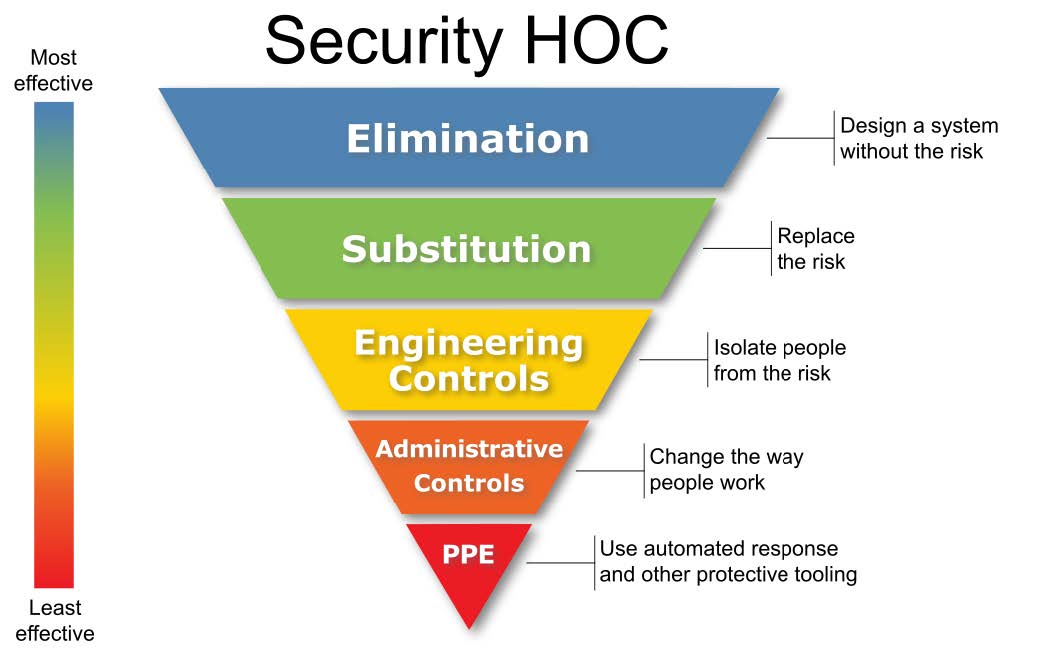
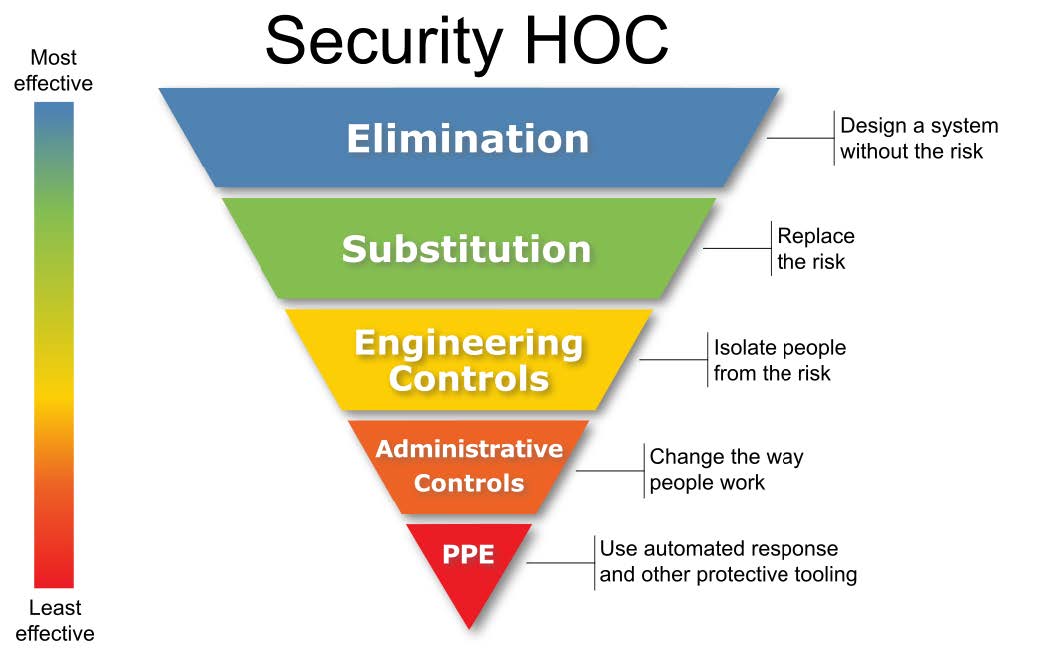
The Hierarchy of Controls.
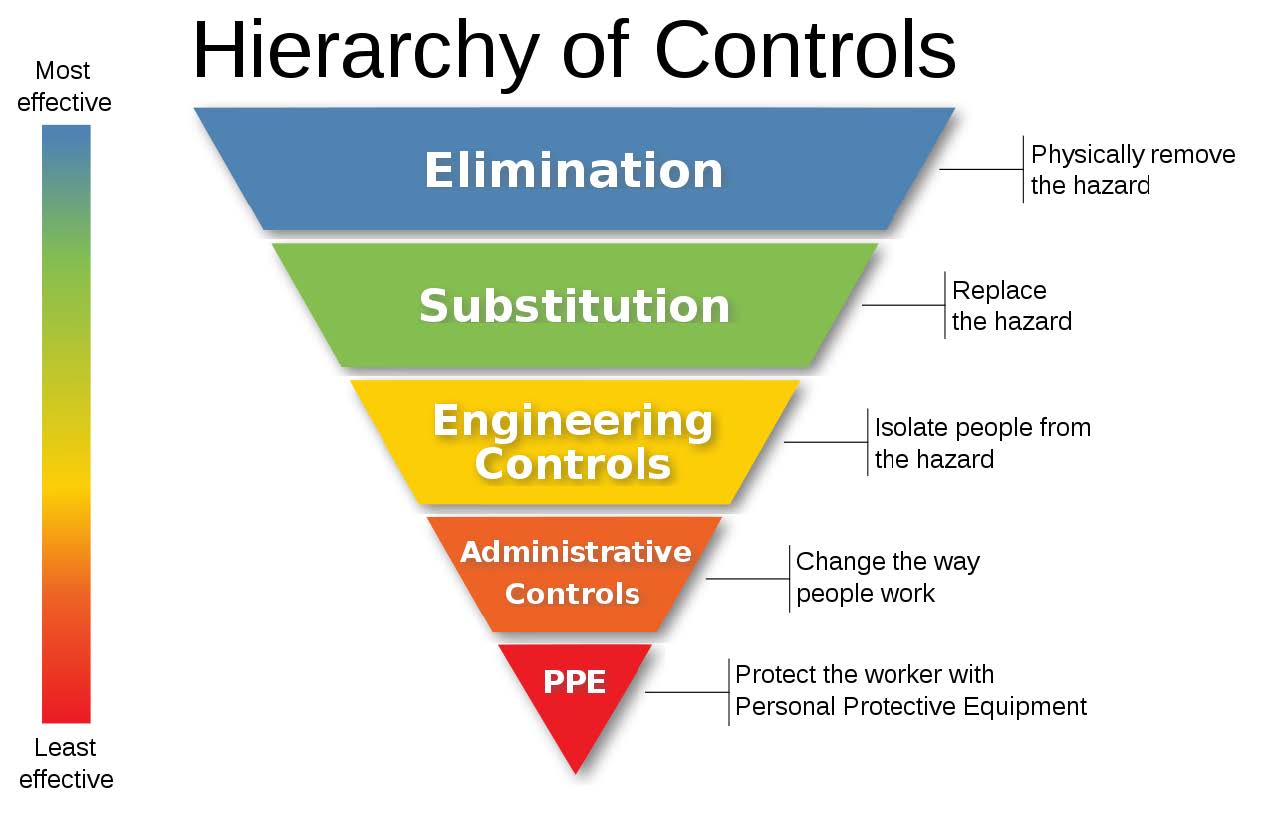
Out of all the measures that you can possibly take to minimize risk, some are more effective than others.
On the lowest rung, the last line of defense, and also the least effective, you have Personal Protective Equipment. Let’s go back to the chlorine spill. The bad thing has already happened. The truck driver loaded up acid in the bleach tank. The driver was overcome by the poison gas so he couldn’t shut off the pump. If he had a respirator at hand, then he could’ve shut down the pump and stopped the leak from getting worse. It wouldn’t have prevented it, but it would’ve reduced the number of injuries.
Further up, we got administrative controls. Changing the way people work! The operator of the facility could’ve been present to make sure that the truck driver loaded up the correct fill line. The fill lines could’ve been correctly marked — thus reducing the risk of a fuckup.
Even more effective would’ve been some engineering controls. Isolating people from the hazard. Making the connectors incompatible. The facility still deals with acid and bleach, but it wouldn’t have been physically possible for the truck driver to load up the wrong chemical.
Substitution. What if the facility could use something else instead of bleach, let’s say sodium hydroxide (lye). Yeah, it’s still dangerous, but much less so. You still got strong, nasty chemicals, but at least when you mix them up it won’t poison the entire city. You’re noticing how, the further up we go, the stronger the controls are. Way more effective.
Elimination. What if the facility could produce the protein, and the spirits, and the starch or whatever without needing to use strong acids or what have you? It would completely eliminate the risk. You’re also noticing how, the further up in the controls you go, how much of a pain in the ass it is to actually implement them. There’s no way anyone is gonna tear down the entire facility to build a new one that uses a different process, assuming it’s even possible in the first place. I’ll get back to that in a sec.
But first, let’s take a look at how such an approach would look in security.
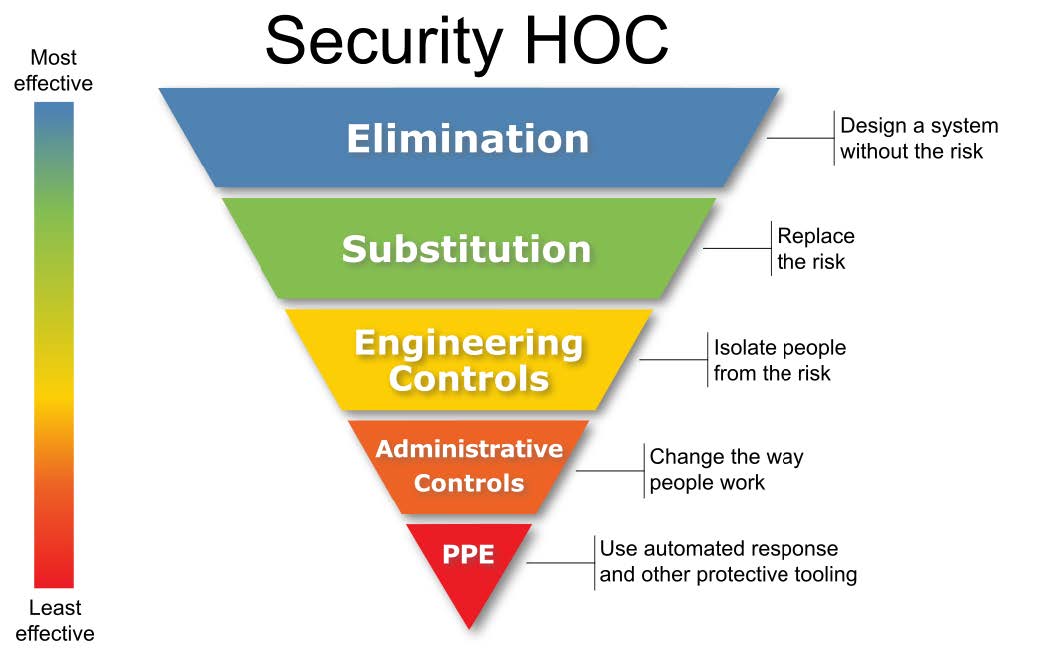
Let’s go back to that example. An engineer was trying to synchronize their environment across machines. They were uploading the files to github on one computer and downloading them on another. They accidentally put a credential in one of them and uploaded it to GitHub. Long day for security.
Let’s go up the hierarchy of controls.
What I didn’t mention is that it was an AWS credential. AWS runs crawlers on GitHub, so if you post a credential it will quickly add a Credential Compromised policy on the credential, locking it down so you can’t mine bitcoin with it. It doesn’t prevent everything, but it’s a quick and dirty guardrail. Personal Protective Equipment, as it were. It bought us some time to rotate the credential.
By the way, if you were here last year, this was the same credential I talked about then — the one that, when we tried to rotate it, it resulted in a complete and total clusterfuck because AWS didn’t tell us that it’s actually not possible to rotate it without breaking everything. Hit me up later for some story time.
Administrative controls: the engineer could’ve used a different mechanism to synchronize their environment. Maybe SFTP or something. We could’ve had a policy in place to double-check for credentials before pushing to GitHub. Engineering controls. The reason they had that credential was because they needed it to troubleshoot. If there was an established troubleshooting process that included a step to remove the credential from the environment once it was no longer needed, it would’ve reduced the risk.
Engineering controls: what if the engineer had a special tool to synchronize the environments that didn’t go through github? What if there was a mechanism to prevent you from committing a credential to code? (by the way, I built something like that a long time ago, it’s called secret-shield, it used git hooks to prevent you from committing credentials to code).
Substitution: the credential had full read-write access to a ton of data. What if the engineer could do the troubleshooting without that credential? Maybe a credential that only gave you access to file metadata.
Elimination: why was the credential needed? Was it possible to create a process that didn’t require credentials in the first place and instead used something like AWS roles?
The further up you go the hierarchy, the more effective the controls are. But it’s more expensive and time consuming.
Telling the person to not fuck up in the future and giving them a checklist to follow is easy. But mistakes can still happen.
Putting in engineering controls is harder, but you can set up guardrails in existing processes and systems.
Substitution and elimination are your best bet, but it’s virtually impossible to do it once a system has been built. That’s why the whole “move security to the left” is so important — you go in early enough in the design process, you can eliminate the risk, or replace it with a lower risk.
You can get to these measures through a root cause analysis. But what the hierarchy of controls gives us is an instant heuristic. A way to look at a problem and instantly assess the risk, and come up with good recommendations.

Here’s another example. This happened on December 13, 1978 at the Siberian Chemical Combine. Workers were doing various things with plutonium ingots, the report was very vague as to what exactly they were doing with them. They were using it for bombs, that’s what they were using it for. The Siberian Chemical Combine was part of the USSR’s nuclear program.
Anyway, they had the plutonium ingots in these little boxes and they had to move them around throughout the process. They had a very, VERY specific set of steps that they were not allowed to deviate from.
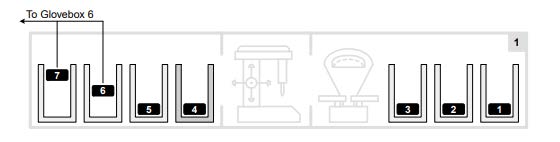
(intentionally vague) So first thing is to move that plutonium ingot from that box over there to this other box. Then you had to load a couple more from an adjacent area and put them in the correct boxes in the correct order. First this one then this one.
You then had to unload them into these other areas, and move them in this order: first this one goes, then this one, then this one.
By the way you can’t see inside the boxes very easily, so you have to make sure that you follow the process to the letter.
Oh, and don’t fuck up. There’s two ingots in that box over there. You can’t see inside it so you better not have skipped a step in the check list. You’re supposed to move them in a very specific order. Because if you put too much plutonium into one box… well… bad shit happens.
The day of the accident there was a fuckup. There was some confusion about the steps, they forgot to move the ingots out of that box, and…
They loaded up too much plutonium. It instantly went kaboom. Thankfully not a full on nuclear explosion — it blew the container and the reaction immediately died down. But eight people were irradiated, some with long-term medical issues.
How many of you have a checklist that must be followed in the EXACT CORRECT ORDER or shit hits the fan? I have a few examples.
We got a checklist to create a new SAML role in AWS and connect it to our identity provider. The sequence of steps is very clear. But if you deviate, you might just accidentally give everyone in the company admin access. Don’t fuck up!
I see checklists like that EVERYWHERE, and not just at my company. How to create a new s3 bucket. There’s a step there to enable encryption and block public access. Don’t forget!! Don’t fuck up!
You already know that “don’t fuck up” is lousy. But back to the hierarchy of controls. You can use this. You can immediately rank various solutions. The checklist is an administrative control. Making a tool to create an s3 bucket for you is an (engineering control). Having a process that doesn’t need you to create 1000 SAML connectors is even better (substitution). Not needing a bucket with personal data on it in the first place is even better (elimination).
You can take it to management when there’s pushback, and say, see, all these regulatory bodies say that “don’t fuck up!” is not good enough! You can propose better solutions. Management loooves charts. You can use this.
There’s another reason I brought up the plutonium accident. One person was supposed to follow this very specific checklist, right? But they were under pressure from management to move things along quickly — after all, it was the cold war, they needed those nukes. The operator needed to leave his workstation to do other tasks, so he asked someone for help with moving the plutonium. When he came back, he didn’t check whether the steps were followed properly — he had a deadline, and just assumed. And that’s what caused the accident.
I see it all the time in security. That credential leak? There were management pressures to troubleshoot the system, and it was really hard to go back and forth with the infrastructure team to get the access they needed. So they used an existing credential that had those permissions. Yeah it was a machine cred, nobody was supposed to touch it, but it did the job. They had to get their env up and running as fast as possible, so they just assumed that it was safe, that there were no credentials in those files that went on github.
The control in place was “please don’t touch this credential”. And this is an… administrative control. Administrative controls are comfortable. It’s really easy to slap on a policy and say, well, this rule reduces risk. And it does. But administrative controls are very susceptible to pressure. It’s easy to cut corners, especially if you need to get the job done.
Developers who are used to working with machine credentials when they need the extra access to troubleshoot something. Sales engineers who create personal AWS accounts to test various setups. Business people sharing passwords in slack.
And you keep doing it, because nothing bad happened this time, or last time, or the previous 100 times, stretching back years.
This is so common there’s even a term for it: normalization of deviance.
NORMALIZATION OF DEVIANCE
It’s when problematic, unsafe behavior becomes more and more insidious throughout the years. It starts out small, you cut a corner once, or see something that’s out of spec once, but it’s fine, so you ignore it this time, you’ll deal with it later. The more you do it and nothing happens, the less risky it seems. It seems normal. And you have a job to do, and you’ll get to it eventually. Maybe there’s even a card in your backlog to fix it. Maybe you keep pushing it sprint after sprint.
There’s plenty of famous exmaples. Did you know that in the space shuttle Challenger disaster, the components that were at fault in the explosion — the o-ring seals that kept the rocket boosters together — failed multiple times before the disaster? They had a failure in 1981. They had one in 1984. They had one in 1985. And it was fine every time. The exact same failure happened in ‘86 during the Challenger launch, except this time it was slightly worse. And disaster happened.

A cable car crashed in Italy not too long ago. The safety brake kept malfunctioning, it would keep engaging when it wasn’t supposed to — these brakes are designed to fail safe, after all, which is good for safety but can be really burdensome if it keeps happening — so the maintenance crew would just disable it until they could get it working again. This happened for years — since at least 2014 they’ve had rides without a working safety brake. And nothing bad happened. But in 2021, after a seven-year record of nothing bad happening, an accident occurred, the cable car fell, and there was no emergency brake to stop it.

I’ll end the examples there. You get the picture. I’ll get to my final point.
It’s really obvious to us right now how reckless and negligent some of these disasters that we talked about are. Disabling emergency brakes? Not checking whether there was enough plutonium to go kaboom? These problems creep up over time.
That’s why you need stronger controls. Engineering controls. Substitution and elimination. Stuff that won’t get tired over the years. Layers of controls, as far up the hierarchy as you can.
That’s why you need a strong security culture. A culture that will pay attention when things aren’t right, and not let things slide. So that when the controls fail, you’ll know, and you’ll get organizational buy-in and willingness to fix it sooner rather than later.
That’s why you need a strong framework. Something you can point to to say, “this isn’t enough”. A process isn’t enough, a checklist isn’t enough, a policy isn’t enough, you need proper guardrails.
And above all, when you get a whiff that your controls failed, pounce on that. That’s your chance to make real change.
Remember at the beginning of the talk, when I asked you if you’d ever almost fucked up bad? Maybe you were on the verge of typing up a command that nuked an entire database. Maybe you were in the wrong AWS region and were about to open up the wrong security group to the public. Maybe you were just tired and forgot to run your command with --dry-run, but a typo saved you. Maybe these examples are oddly specific.
Maybe it wasn’t you. Maybe it was that engineer who accidentally made a bucket public but you got an alert and managed to shut it down. Maybe a credential leaked but you had an oncall rotation and managed to nuke it before someone hacked your company.
When you almost fuck up, that means all your controls failed. All the conditions were right for a disaster, and only blind luck stopped it from happening. You just had a near miss.
You better treat that as if the disaster actually happened. Don’t push it back again, don’t put it in the backlog. Think of it as a game over that the engineering gods pulled you back from. Make sure that the organization will do a goddamn postmortem on it. Because the conditions that made that happen are still there, and next time you won’t get so lucky.
And telling people to be more careful won’t cut it. “Just don’t fuck up” is not an effective control.
Thank you.